About
Currently, either crowdsourced or fully automatic methods are used to create training data for Natural Language Inference (NLI) tasks, like semi-structured table reasoning. In this paper, a realistic semi-automated system for tabular inference's data augmentation is developed. Our methodology creates hypothesis templates that may be applied to similar tables rather than manually creating a hypothesis for each table. Additionally, our paradigm calls for the construction of logical counterfactual tables based on premise paraphrasing and human-written logical restrictions. We found that our methodology could produce examples of tabular inference that resembled those made by humans. This could help with training data augmentation, particularly in the case of limited supervision.
Framework
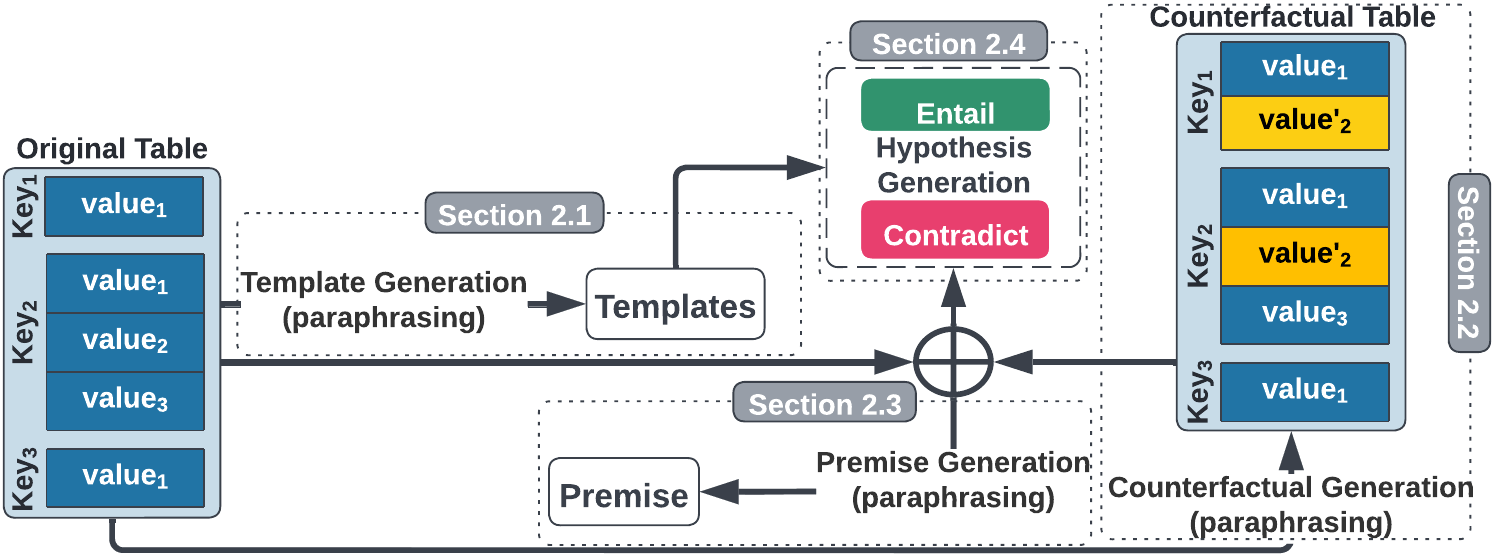
Our framework includes four main components:
i. Hypothesis Template Creation
The row attributes (i.e., keys) for a particular category of tables (for example, movies) are mostly shared across all tables (e.g., Length, Producer, Director, and others). It is advantageous to write key-based rules for specific table categories in order to produce logical hypothesis sentences. We develop key-based rules for the following reasoning types: Temporal reasoning, numerical reasoning, spatial reasoning, and common sense reasoning are the four types of reasoning.

ii. Rational Counterfactual Table Creation
We alter the original table in one or more of the following ways to create a counterfactual table: Maintaining the row in its current state without making any changes, adding a new value to an existing key, replacing an existing key-value pair with counterfactual data, deleting a specific key-value pair from the table, adding missing new keys (i.e., a key from (n k)), and adding a missing key row to the table are all examples of options. For the purpose of creating counterfactual tables, a subset of operations is chosen randomly for each row of an existing table with a predetermined probability p (a hyper-parameter).To guarantee logical consistency in the generated sentences, we impose crucial key-specific constraints when building these tables.

iii. Paraphrasing of Premise Tables
The lack of linguistic variety is a major issue with grammar-based data generation methods. As a result, we use both automated and human premise table parsing to address the diversity issue. We write at least three to five simple paraphrased sentences of the key-specific template for each key for a given category.

iv. Automatic Table Hypothesis Generation
Once created, the templates can be used to automatically fill in the blanks from the entries of the considered tables and generate logically rational hypothesis sentences. To generate contradictory sentences, we choose a value at random from a set of key values shared by all tables to fill in the blanks. This substitution ensures that key-specific constraints, such as key-value type, are followed. Furthermore, we ensure that entail contradict pair is created using a similar template with minimal token modification.

Data Quality Evaluation

Experimental Results
We did our analysis in broadly 4 settings:
a. Evaluation
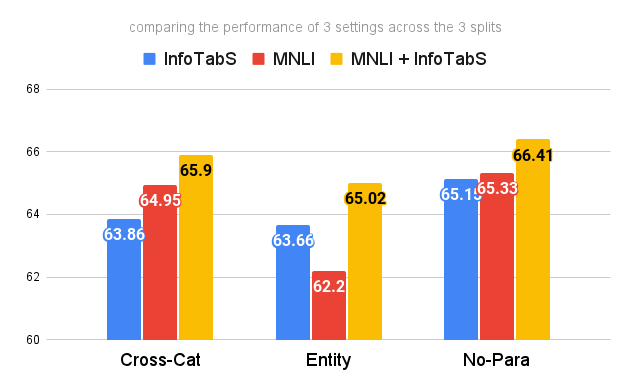
b. Standalone
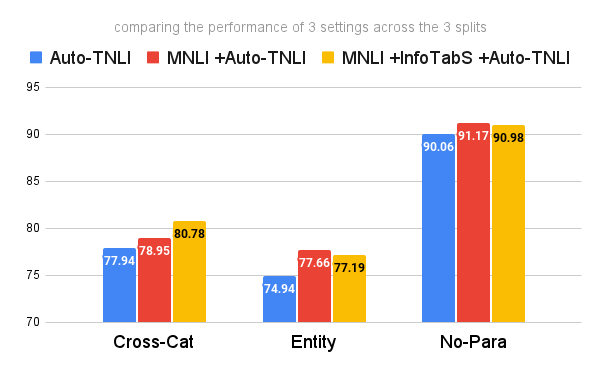
c. Augmentation
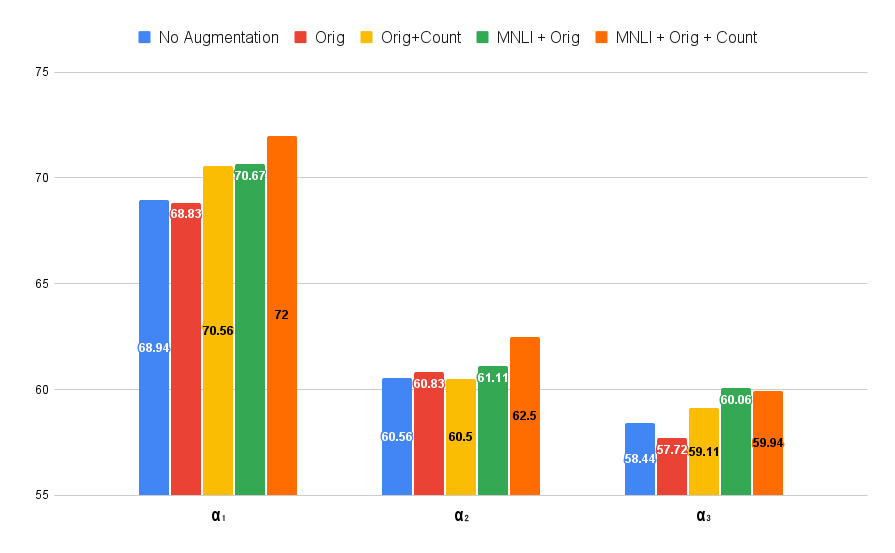
d. Limited supervision
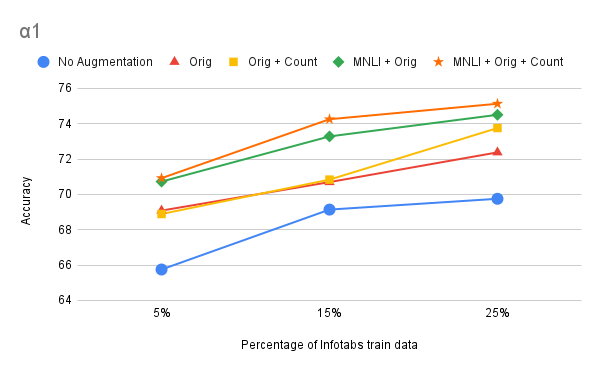
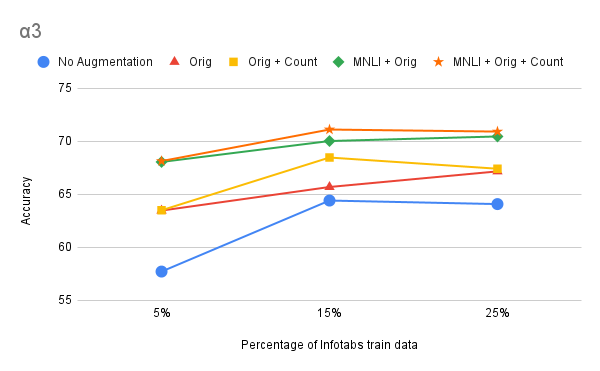
Conclusion
We presented a semi-automatic framework for extracting information from tabular data. We generate AutoTNLI using a template-based approach. AutoTNLI was used for both TNLI evaluation and data augmentation. Our experiments show that AutoTNLI and, by extension, our framework are effective, particularly in adversarial settings. In the future, we hope to create more lexically diverse and robust datasets and investigate whether the addition of neutrals can improve these datasets.
People
The following people have worked on the paper "Realistic Data Augmentation Framework for Enhancing Tabular Reasoning":




Citation
Please cite our paper as below if you use AutoTNLI.
@inproceedings{kumar-etal-2022-autotnli,
title = "Realistic Data Augmentation Framework for Enhancing Tabular Reasoning",
author = "Kumar, Dibyakanti and
Gupta, Vivek and
Sharma, Soumya and
Zhang, Shuo",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Online and Abu Dhabi",
publisher = "Association for Computational Linguistics",
url = "https://vgupta123.github.io/docs/autotnli.pdf",
pages = "",
abstract = "Existing approaches to constructing training data for Natural Language Inference (NLI) tasks, such as for semi-structured table reasoning, are either via crowdsourcing or fully automatic methods. However, the former is expensive and time-consuming and thus limits scale, and the latter often produces naive examples that may lack complex reasoning. This paper develops a realistic semi-automated framework for data augmentation for tabular inference. Instead of manually generating a hypothesis for each table, our methodology generates hypothesis templates transferable to similar tables. In addition, our framework entails the creation of rational counterfactual tables based on human written logical constraints and premise paraphrasing. For our case study, we use the InfoTabS (Gupta et al., 2020), which is an entity-centric tabular inference dataset. We observed that our framework could generate human-like tabular inference examples, which could benefit training data augmentation, especially in the scenario with limited supervision.",
}Acknowledgement
We thank members of the Utah NLP group for their valuable insights and suggestions at various stages of the project; and EMNLP 2022 reviewers their helpful comments. We thank Antara Bahursettiwar for her valuable feedback. Additionally, we appreciate the inputs provided by Vivek Srikumar and Ellen Riloff. Vivek Gupta acknowledges support from Bloomberg's Data Science Ph.D. Fellowship.